Dal raduno di OpendataSicila sui Linked Open Data, alle ontologie da applicare alle PA
Il 9 e 10 novembre 2018 si è tenuto nel Palazzo dei Normanni di Palermo (sede del Parlamento siciliano) il raduno annuale della comunità nazionale di Opendatasicilia = http://ods2018.opendatasicilia.it

Quest’anno il tema scelto è stato: i linked open data. Protagonisti e propositori del tema sono stati Giovanni Pirrotta e Davide Taibi. Due persone che da anni lavorano sulle ontologie, linked open data e sul web semantico. All'evento hanno partecipato anche altri soggetti provenienti da diverse parti d’Italia molto competenti sui linked data e sulla modellazione delle ontologie, come ad esempio Giorgia Lodi (che lavora all'Agenzia per l’Italia Digitale proprio sulle ontologie), ed altri esperti le cui presentazioni sono disponibili qui: http://ods2018.opendatasicilia.it/#presentazioni.
Hanno partecipato anche aziende interessate al riuso dei dati provenienti da diverse PA in maniera massiva, come Opencontent, Engineering, SAS, Elmi, Olomedia.

L’evento è stato caratterizzato da un alto livello di competenza dei soggetti partecipanti sui linked open data, sulle ontologie e sui vocabolari controllati.
Io ho partecipato da principiante
Da dipendente di un grande ente pubblico (Comune di Palermo), con un interesse culturale al mondo dei dati ho avuto la possibilità di approfondire come l’interoperabilità delle banche dati e dei servizi pubblici è resa possibile proprio grazie all'uso delle “ontologie” nei software usati. Vediamo in seguito come con qualche esempio.
L’ontologia informatica su Wikipedia: “descrivere il modo in cui diversi schemi vengono combinati in una struttura dati contenente tutte le entità rilevanti e le loro relazioni in un dominio. I programmi informatici possono poi usare l’ontologia per una varietà di scopi, tra cui il ragionamento induttivo, la classificazione, e svariate tecniche per la risoluzione di problemi.”
L’articolo 4 del Piano Triennale per l’informatica nella PA definisce i vocabolari controllati e modelli dei dati come “un modo comune e condiviso per organizzare codici e nomenclature ricorrenti in maniera standardizzata e normalizzata (vocabolari controllati) e una concettualizzazione esaustiva e rigorosa nell'ambito di un dato dominio (ontologia o modello dei dati condiviso”).

Come si vede nell'immagine di sopra, l’ontologia (in questo caso l’ontologia dell’Assemblea Regionale siciliana — OpenArs— prodotta da Davide Taibi e Giovanni Pirrotta) viene rappresentata come un grafo contenente una rete di relazioni tra classi (Deputato, Atto, Gruppo Parlamentare, ecc).
Nell'ambito del progetto OpenARS è stata definita una ontologia per descrivere le diverse tipologie di dato e le interconnessioni che intercorrono tra i dati che sono stati raccolti nel progetto.
In questo caso Giovanni Pirrotta e Davide Taibi sono partiti dal sito istituzionale dell’Assemblea Regionale Siciliana — attraverso tecniche di scraping — per costruire OpenArs, un portale parallelo in cui i dati estratti dal portale istituzionale vengono rappresentati con una struttura efficace e che illustra in maniera organizzata le diverse relazioni tra le entità che fanno parte dell'ambito dei lavori di competenza dell’Assemblea Regionale Siciliana. Loro (Giovanni e Davide) esporrebbero il loro lavoro con termini tecnici più adeguati al mondo linked open data, ma nel mio livello di conoscenza delle ontologie riesco a trovare questa definizione.
Attenzione: questo post …
In questo post non mi sogno minimamente di entrare nel cuore del mondo delle ontologie. Non ne ho le competenze né conoscenze professionali per farlo. Ho iniziato da poco a studiare con interesse questo ambito. E sicuramente quanto scrivo può essere per me una conferma di quanto compreso finora. Voglio solo partire da tutto quello che è stato trattato ampiamente durante i due giorni del raduno per fare un collegamento con il mondo “reale” della pubblica amministrazione che non utilizza frequentemente le ontologie e i vocabolari controllati nelle piattaforme informatiche, motivo per il quale non esiste quella “interoperabilità” tanto ipotizzata, ricercata, citata in centinaia di presentazioni power point delle PA e articoli di blog specializzati sull'agenda digitale, ma quasi mai “praticata”.
Ripasso con i suggerimenti di Antonino Lo Bue:
- i
vocabolari controllatisono delle tassonomie di termini (e.s. le tipologie possibili di un evento, i generi musicali), intese come controllate perché sono limitate ad alcuni termini. - Le
ontologiesono un insieme di relazioni, proprietà’ e restrizioni che servono ad esprimere un dominio di conoscenza.
Non sempre/per forza una ontologia deve usare dei vocabolari controllati, potrei ad esempio creare una mia ontologia per descrivere un mio dominio senza dover usare termini controllati.
Grazie Antonino :)
Usare ontologie e vocabolari controllati
Di seguito l’esempio di un ontologia degli eventi pubblici:
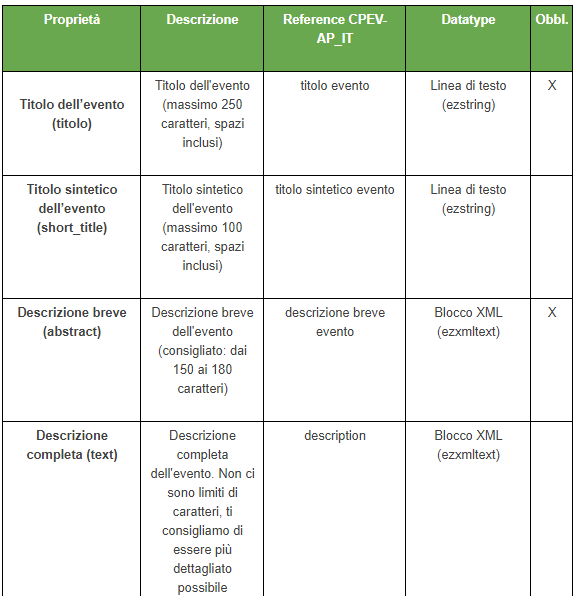
E qui di sotto il vocabolario controllato sugli eventi pubblici (dal repository delle ontologie e dei vocabolari controllati sviluppati nell’ambito delle azioni previste dal piano triennale per l’informatica nella PA 2017–2019 e a supporto del lavoro da svolgere per l’elenco delle basi di dati chiave):

Gabriele Francescotto (Opencontent) mi dice:
- l’ontologia definisce l’idea “platonica” di come deve essere fatto un evento (quella di OntoPiA si chiama CPEV-AP_IT https://github.com/italia/daf-ontologie-vocabolari-controllati/blob/master/Ontologie/CPEV/0.3/CPEV-AP_IT.ttl ); il valore dell’ontologia sta nel fatto che viene definita al centro (meglio se attraverso un percorso partecipativo, come è avvenuto per gli eventi) in modo tale che qualsiasi software abbia un punto di riferimento preciso a cui convergere. Se l’ontologia subisse variazioni, i software che producono dati dovranno adattarsi adattarsi (per questo lato nostro è fondamentale prevedere sistemi di allineamento automatico a livello di base dati, interfacce di inserimento dati, web service di importazione, motore di ricerca interno, Rest API, ecc…)
- a fianco dell’ontologia, vengono definiti i vocabolari controllati (es. tipologie di evento: mostra, festival, corso, …) eccoli qui: https://github.com/italia/daf-ontologie-vocabolari-controllati/blob/master/VocabolariControllati/public-event-types/public-event-types.csv ; anche questi vanno definiti al centro (AgID) e devono essere riusati da tutti i software; sono in openagenda sono usati dai redattori per classificare e dagli utenti finali per filtrare gli eventi (quindi sono importanti per focalizzare l’interesse dell’utente sul suo effettivo bisogno); ognuno può estenderli a livello locale, aggiungendo tipologie di evento, per classificare gli eventi in maniera più precisa
- in Openagenda abbiamo definito un’altra cosa: il modello dati (logica con cui immettiamo i dati nel nostro database, tabella verde: https://content-classes.readthedocs.io/it/latest/docs/Eventi%20pubblici%20%28CPEV-AP_IT%29.html) in funzione delle ontologie e dei vocabolari controllati: dobbiamo essere certi di raccogliere alla fonte tutte le informazioni che servono per soddisfare quanto richiesto dall’ontologia (ad esempio, le date di inizio e fine dell’evento devono essere codificate in un certo modo); quindi cerchiamo di fare in modo che le nostre classi, che definiscono la struttura dati del nostro database, coincidano con le classi definite nell’ontologia. In questo modo, sarà molto semplice generare un JSON-LD in linea con quanto previsto dalle ontologie.
Sui servizi pubblici, facciamo esattamente la stessa cosa:
- prendiamo l’ontologia definita in OntoPiA (CPSV-AP_IT);
- prendiamo tutti i vocabolari controllati (OntoPiA ne definisce 5: https://github.com/italia/daf-ontologie-vocabolari-controllati/tree/master/VocabolariControllati/classifications-for-public-services);
- adattiamo la struttura dati del nostro database ai requisiti dell’ontologia.
Grazie Gabriele per chiarire a me e ad altri concetti e significati delle ontologie e vocabolari controllati facendo esempi concreti.
Questo vocabolario controllato è utilizzato dalla società Opencontent nello sviluppo del software “Open Agenda” che l’Associazione dei comuni Trentini, il comune di Udine, il comune di Bolzano adottano per pubblicare gli eventi culturali nei propri territori. Queste PA utilizzando lo stesso vocabolario controllato che permette a chiunque di rendere interoperabili i dati che stanno dietro i software e che sono pubblicati come open data. In questo caso è possibile fare linked open data cioè è possibile mettere in diretta relazione i dati degli eventi pubblici di queste PA. Se i dati di queste PA che vengono fuori dall'applicativo OpenAgenda sono pubblicati in forma di open data (formati ad es.: json, xml, csv, json-ld), è possibile unirli e — ad esempio — creare un applicazione per dispositivi mobili o un servizio web che da la possibilità ad un cittadino/turista di scegliere la città in cui ci sono più eventi culturali ed artistici di particolare interesse personale (musica, pittura, letteratura, ecc.).
Nei casi in cui le PA utilizzano lo stesso vocabolario controllato, riferibile ad una particolare ontologia per rappresentare (in questo caso gli eventi pubblici) un servizio ben preciso che viene erogato pubblicamente, i dati che derivano da quel software che adotta la stessa ontologia (e vocabolario controllato) sono dati perfettamente confrontabili tra loro, in quanto aventi la medesima struttura (per semplificare: lo stesso nome colonna in diversi database se vogliamo immaginarlo come colonna di un formato tabellare).
Ecco, ho fatto l’esempio che descrive una buona prassi nel campo delle ontologie. Perchè buona prassi? Perchè un ontologia dopo essere stata definita concettualmente, modellata nel dettaglio, e su di essa costruito o adottati uno o più vocabolari controllati di classi, la stessa (ontologia) viene applicata ad un software della PA per gestire processi amministrativi necessari ad erogare servizi pubblici. Cioè le ontologie devono essere adottate dagli applicativi gestionali per esercitare la loro funzione: definire e rendere chiara a tutti la struttura dati e le relazioni tra i propri elementi interni (classi, categorie, entità).
Quello che invece non avviene nelle PA
Non avviene l’utilizzo diffuso di ontologie già modellate e usabili! Dalla due giorni del raduno ODS (Opendatasicilia) sui linked open data ho capito che esistono ontologie modellate, pronte per l’uso. Vedi l’esempio delle ontologie nel portale del Data & Analytics Framework (a cura del Team Trasformazione Digitale + AGID) .
- Ontologia delle Condizioni di Accesso
- Strutture ricettive
- Ontologia degli Indirizzi/Luoghi
- Ontologia delle Organizzazioni — Profilo applicativo italiano
- Eventi Pubblici
- Core Public Service Vocabulary — Il profilo applicativo italiano (CPSV-AP_IT) Servizi Pubblici
- CPV-AP_IT: Core Person Vocabulary — profilo applicativo italiano — Ontologia delle persone (vorrei capire la differenza con l’ontologia FOAF — Friend Of A Friend)
- Ontologia per le lingue
- Ontologia per le unità di misura
- Ontologia dei Parcheggi
- Ontologia dei Punti di Interesse — Profilo applicativo italiano
- Ontologia dei Prezzi, Offerte e Biglietti — Profilo applicativo italiano
- Ontologia dei Contratti Pubblici — Profilo applicativo italiano
- Ontologia dei Ruoli — Profilo applicativo italiano
- Ontologia per i social media — internet
- Ontologia del Tempo — Profilo applicativo italiano
E altri 23 vocabolari controllati.
Domanda: quante PA utilizzano nei loro software gestionali queste ontologie e vocabolari controllati dell’AGID?
Utilizzare per le varie PA queste ontologie e vocabolari significherebbe, usare lo stesso linguaggio nella gestione digitale di processi amministrativi, con il risultato che i dati derivanti da questi applicativi sarebbero direttamente confrontabili tra di loro e messi in relazione diretta, dando vita al famoso 5° livello del formato dei dati (LOD= linked open data) nella scala di Tim Berners Lee.
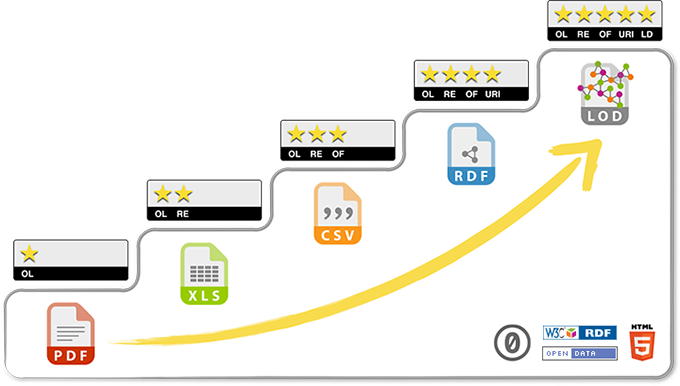
Il problema è: “usare” le ontologie già esistenti nei processi della pubblica amministrazione!
Dal raduno di Opendatasicilia ho capito l’importanza dell’uso delle ontologie e dei vocabolari controllati nel lavoro svolto dentro la pubblica amministrazione per realizzare l’interoperabilità semantica.
Definizione di interoperabilità semantica: «possibilità, offerta alle organizzazioni, di elaborare informazioni da fonti esterne o secondarie senza perdere il reale significato delle informazioni stesse nel processo di elaborazione» (fonte: «Linee Guida per l’interoperabilità semantica attraverso i Linked Open Data» AgID).
Ma non ho capito come fare applicare queste ontologie e vocabolari controllati alle singole PA all'interno dei loro software gestionali.
- Che consapevolezza hanno oggi migliaia di dirigenti/dipendenti della PA sull'importanza dell’utilizzo delle ontologie e dei vocabolari controllati?
- Chi vigila su questo mancato utilizzo? Quale ente?
- L’uso delle ontologie e dei vocabolari controllati, benché raccomandato dal Piano Triennale per l’informatica nella PA, rientra nelle analisi e re ingegnerizzazione dei processi amministrativi nei momenti in cui si redigono capitolati d’appalto per acquistare software, necessario a gestire in modalità digitale ciò che fino a ieri si gestiva con la carta (transizione al digitale)?
Attenzione a non perdere un opportunità unica per applicare ontologie e vocabolari controllati nei software delle PA: PON METRO Asse 1 Agenda Digitale
Entro il dicembre 2020, 14 città metropolitane italiane utilizzeranno i fondi del PON METRO 2014–2020 (Asse 1) per acquistare piattaforme digitali e software necessari a realizzare servizi di Agenda Digitale. Si spenderà — in 14 città — la somma di quasi 152 milioni di euro in servizi/infrastrutture ICT.
Si aprono spiragli di speranza
Il 6 novembre 2018 all’AGID si è tenuta una riunione, organizzata dalla nuova Direttrice dell’AGID, dottoressa Teresa Alvaro, con le 14 città metropolitane per un confronto sull'attuazione del Piano Triennale dell’informatica nella PA 2017–2019 e sull'attuazione dei progetti del PON METRO Asse 1 agenda digitale. Ho approfittato della mia partecipazione a questa riunione, assieme al mio dirigente (dott. Gabriele Marchese, Responsabile Transizione al Digitale del comune di Palermo), per sottolineare l’importanza dell’utilizzo delle ontologie e dei vocabolari controllati nella strutturazione del software delle PA.
Anche la nuova direttrice dell’AGID,
nel suo intervento di fine riunione, ha confermato l’importanza dell’uso di un unico linguaggio/codice comune alle numerose PA per la gestione dello stesso servizio! A questo link il comunicato stampa dell’AGID sull'incontro.
E allora?
Allora credo sia importantissimo fare in modo da replicare il format di eventi come quello del raduno 2018 di Opendatasicilia sui Linked Open Data in cui il mondo competente sulle ontologie (ad esempio: Giorgia Lodi, Davide Taibi, Giovanni Pirrotta, Ricccardo Grosso, i gruppi delle presentazioni del raduno e tante altre persone a me sconosciute in Italia) si mette in contatto diretto con chi lavora nei comuni, nelle regioni, nelle Aziende sanitarie regionali (dirigenti e dipendenti).
Fare un Team di esperti,
che lavora costantemente a fianco del personale pubblico delle città metropolitane per contaminare questa conoscenza sulle ontologie e vocabolari controllati da applicare ai processi amministrativi gestiti con software.
Farlo ora,
immediatamente prima di spendere i tanti fondi pubblici del PON METRO Asse 1 Agenda Digitale (152 milioni di euro), prima che sia troppo tardi, prima cioè di far costruire cattedrali digitali nel deserto a tante PA i cui servizi e dati non si parleranno mai, negando l’interoperabilità tanto nominata (nelle slide e nei post di blog) in questo periodo storico.
Passare dallo #slideware (come dice il mio dirigente) ai #fatti.
#slideware: tendenza ad esporre tante presentazioni fighe su power point con intenzioni di raggiungere obiettivi senza poi realizzare nel tempo quanto illustrato nelle stesse presentazioni. Sinonimo di “tanto fumo e poco arrosto”.

Un idea di partenza: creare l’ontologia di ogni servizio pubblico censito dal comune nella cosiddetta “carta dei servizi”.
Un idea potrebbe essere, partire dal catalogo della carta dei servizi di un comune (esempio), per costruire un ontologia per ogni specifica carta dei servizi, che sia valida (cioè applicabile) per tutti i comuni.
Al fine di rendere unica la carta dei “servizi allo sport”, ad esempio, si crea l’ontologia dei “servizi allo sport” e si adotta per tutti i comuni d’Italia. Lo stesso si fa per la carta dei “servizi al turista”, per quella dei “servizi del verde”, ecc. Quindi tutti i comuni d’Italia che adotteranno questa specifica ontologia dovranno solo utilizzare le stesse classi e categorie già modellate in questa ontologia, senza inventarsi localmente nulla! Se tutti i comuni utilizzeranno quell'ontologia, e vocabolari controllati aderenti a quell'ontologia, è possibile pensare che tutti i comuni avranno dati che possono essere messi in diretta relazione, in quanto aventi tutti la stessa struttura dati, generando così i linked open data.
Mi fermo, per capire, dai bravi delle ontologie, se ho capito bene finora (sulle ontologie). O se diversamente devo ricominciare a studiare da zero. E’ solo un post di verifica.
